

 Programlama Akademi
Programlama Akademi
Üretici Model - Generative Model Nedir
Giriş
Üretici model (Generative Model), eğitim verilerine benzer yeni veriler oluşturmak için tasarlanmış bir makine öğrenimi modelidir. Üretici yapay zeka (Generative Artificial Intelligence - AI) modelleri, eğitim verilerinin kalıplarını ve dağılımlarını öğrenir ve ardından bu bilgileri yeni girdilere yanıt olarak özgün içerikler üretmek için kullanır. İçerik oluşturma eylemi, üretici yapay zeka modellerini diğer yapay zeka türlerinden ayıran temel özelliktir. Üretici modeller, insan beyninin yapısını taklit eden gelişmiş sinir ağlarıdır ve eğitim verilerini işlemek ve yeni çıktılar üretmek için karmaşık makine öğrenimi algoritmalarını uygular. Son birkaç yıldır yapay zeka dünyasındaki en büyük gelişmelere üretici yapay zeka modelleri ve bu modelleri geliştirenler öncülük etmiştir. Üretici modeller, yapay zeka ile ilgili haberlerin büyük bir kısmını oluşturmakta ve önemli ölçüde ilgi ve yatırım çekmektedir.
🚀 Yapay Zeka Paketi’ne kaydolarak, üretici yapay bilginizi ileri seviyeye taşıyabilir ve yapay zeka alanında güçlü bir başlangıç yapabilirsiniz!
Üretici Yapay Zeka - Generative AI Nedir?
Üretici yapay zeka - Generative AI, gelişmiş modeller kullanarak bir giriş istemine (input prompt) göre yeni içerikler üreten bir yapay zeka türüdür. Üretici model (Generative Model), verileri ve algoritmaları kullanarak üretici yapay zekanın çalışma sürecini gerçekleştiren bilgisayar programıdır. Üretici yapay zekanın kullanım alanları arasında metin özetleme (text summarization), metin üretimi (text generation), görüntü oluşturma (image generation), 3D modelleme (3D modeling) ve ses üretimi (audio creation) gibi çeşitli uygulamalar bulunmaktadır.
Üretici Modeller Nasıl Çalışır?
Üretici modeller, eğitim verilerindeki kalıpları ve dağılımları tanımlayarak ve bu bilgileri yeni kullanıcı girdilerine dayalı veri üretmek için uygulayarak çalışır. Eğitim süreci, modelin eğitim veri kümesindeki özelliklerin ortak olasılık dağılımlarını (joint probability distributions) tanımasını sağlar. Daha sonra model, öğrendiklerine dayanarak eğitim verilerine benzeyen yeni veri örnekleri üretir. Üretici modeller genellikle denetimsiz öğrenme (unsupervised learning) teknikleriyle eğitilir; yani, etiketlenmemiş büyük miktarda veriyi analiz eder ve bu verilerdeki düzeni kendi başına keşfeder. Modeller, verinin dağılımını belirleyerek içsel bir mantık geliştirir ve bu mantığı yeni veri üretmek için kullanır. Eğitim sürecinde model, gerçek dünya çıktıları ile modelin tahminleri arasındaki farkı ölçen bir kayıp fonksiyonu (loss function) uygular. Eğitimdeki amaç, kayıp fonksiyonunu en aza indirerek üretilen çıktıları gerçeğe mümkün olduğunca yakın hale getirmektir. İçerik üretimi olasılıksal bir süreçtir. Üretici modeller, insanlar gibi "bilgiye sahip olmak" yerine, eğitim sürecinde öğrendikleri kurallara dayalı olarak en olası çıktıyı tahmin etmek için karmaşık matematiksel denklemler kullanır.
Üretici Modeller ve Diğer Model Türleri
Üretici modeller (Generative Models) belirli bir sınıfa ait yeni veriler üretmeye çalışır. Ayırt edici modeller (Discriminative Models) öğeleri bilinen gruplara ayırırken, kümeleme modelleri (Clustering Models) veri kümesindeki öğelerin nasıl gruplandırılacağını belirler. Tahmin edici modeller (Predictive Models) ise geçmiş verilerden yola çıkarak gelecekteki olaylar veya durumlar hakkında tahminlerde bulunur.
Ayırt edici modeller - Discriminative Models, verilerin etiketlerinin veya kategorilerinin bilindiği denetimli öğrenme (Supervised Learning) görevlerinde kullanılır. Birçok ayırt edici model, özellikler ve etiketler arasındaki ilişkileri belirlemeye çalışan ve ardından koşullu olasılığa (Conditional Probability) dayalı olarak yeni verilere sınıf etiketleri atayan sınıflandırıcılardır (Classifiers). Örneğin, balık ve kuş resimlerini ayırt etmek için eğitilmiş bir ayırt edici model, bir resmin balık mı yoksa kuş mu olma olasılığını tahmin edebilir. Görüntü tanıma (Image Recognition), makine öğreniminde sık kullanılan bir sınıflandırma türüdür ve genellikle ayırt edici modellerle gerçekleştirilir. Üretici modeller ile ayırt edici modeller belirgin farklılıklara sahip olsa da, bazen birlikte çalışırlar. Örneğin, üretici çekişmeli ağlar (Generative Adversarial Networks - GANs), bir üretici ve bir ayırt edici modeli rekabet içinde çalıştırarak daha gerçekçi veriler üretmeyi amaçlar.
Kümeleme modelleri - Clustering Models, denetimsiz öğrenme (Unsupervised Learning) görevlerinde veri kümesindeki kayıtları kümelere ayırmak için kullanılır. Benzer öğeleri tanımlayabilir ve ayrıca bu öğeleri diğer gruplardan ayıran farklılıkları öğrenebilir. Kümeleme modelleri, veri kümesindeki öğelerin kaç farklı gruba ayrılabileceğine dair önceden bilgiye sahip değildir. Örneğin, bir pazar araştırmacısı, hedef kitlesindeki alıcı kişiliklerini (Buyer Personas) belirlemek için bir kümeleme modeli kullanabilir.
Tahmin edici modeller - Predictive Models, geçmiş verileri işleyerek makine öğrenimi ve istatistiksel analiz teknikleriyle gelecekteki olaylar hakkında tahminlerde bulunur. İş dünyasında veri odaklı kararlar almak için sıkça kullanılır. Ayrıca, tahmin edici metin hizmetleri (Predictive Text), yüz tanıma (Facial Recognition), dolandırıcılık tespiti (Fraud Detection) ve tedarik zinciri yönetimi (Supply Chain Management) gibi alanlarda da kullanılır.
Üretici modeller - Generative Models, eğitim sırasında etiketlenmemiş (Unlabeled) verilerle eğitilir ve kategorilendirme kriterlerini tersine mühendislik yöntemiyle keşfeder. Yani, belirli bir etikete sahip bir verinin hangi özellikler nedeniyle bu etiketi aldığını anlamaya çalışır. Örneğin, hayvan resimleri üretmek için eğitilmiş bir üretici model, bir balığın diğer hayvanlardan nasıl farklı olduğunu belirleyerek yeni bir balık görüntüsü oluşturabilir. Görüntü üretimi (Image Generation), üretici modellerin yaygın kullanım alanlarından biridir.
Üretici Model Türleri
Farklı mimari yapıları olan birçok üretici model türü bulunmaktadır. Derin üretici modeller (Deep Generative Models), derin öğrenme (Deep Learning) sinir ağları kullanarak veri noktaları arasındaki karmaşık ilişkileri anlamaya çalışan bir alt kategoridir.
- Oto-regresif modeller - Autoregressive Models: Önceki veri noktalarına dayanarak bir dizideki bir sonraki veriyi tahmin eder. Özellikle doğal dil işleme (Natural Language Processing - NLP) alanında güçlüdür.
- Yayılma modelleri - Diffusion Models: Verilere kademeli olarak gürültü ekleyerek yeni veri oluşturur, ardından bu gürültüyü temizleyerek yeni çıktılar üretir.
- Üretici çekişmeli ağlar - Generative Adversarial Networks (GANs): Bir üretici ve bir ayırt edici modeli rekabet içinde çalıştırarak sahte veriler üretir ve bunları gerçek verilerden ayırt edilmesi zor hale getirir.
- Varyasyonel otoenkoderler - Variational Autoencoders (VAEs): Giriş verilerini bir kodlayıcı (Encoder) ile sıkıştırır, ardından bir kod çözücü (Decoder) kullanarak yeni, benzer veriler üretir.
- Akış tabanlı modeller - Flow-Based Models: Basit ve karmaşık veri dağılımları arasındaki ilişkileri tersine çevrilebilir matematiksel işlemlerle öğrenir.
Oto-regresif Modeller - Autoregressive Models
Oto-regresif modeller, bir dizideki bir sonraki öğeyi tahmin etmek için önceki öğeleri değerlendirir. Bu modeller, önceki veriler arasındaki olasılıksal ilişkileri analiz eder ve bu bilgiler doğrultusunda yeni bir bileşeni belirler.
- Oto-regresyon (Autoregression), doğrusal regresyonun (Linear Regression) bir türüdür ve geçmiş değişken değerlerine dayanarak tahmin yapar.
- Lojistik regresyondan (Logistic Regression) farklı olarak, belirli bir olayın gerçekleşme olasılığını değil, belirli değerleri doğrudan tahmin eder.
- Oto-regresif modeller, yinelemeli sinir ağları (Recurrent Neural Networks - RNNs) veya dönüştürücü (Transformer) mimarileri şeklinde olabilir.
Dönüştürücü Modeller - Transformer Models
Dönüştürücüler (Transformers), 2017 yılında ortaya çıkmış ve kısa sürede en yaygın kullanılan oto-regresif model türü haline gelmiştir. Daha önce popüler olan RNN'lerin bazı temel zayıflıklarını gidermiştir:
- RNN'lerin Zorlukları:
- Uzun vadeli bağımlılıkları (Long-range Dependencies) yakalamakta zorlanır.
- İşlemleri sıralı (Sequential) olarak gerçekleştirdiği için hesaplama açısından verimsizdir.
- Dönüştürücülerin Getirdiği Yenilikler:
- Paralel İşleme (Parallel Processing): Dönüştürücüler, dizideki tüm öğeleri aynı anda işler, bu da büyük veri kümeleriyle çok daha hızlı eğitim yapılmasını sağlar.
- Kendi kendine dikkat mekanizması (Self-Attention Mechanism): Dönüştürücüler, dizideki tüm öğelerin birbirine olan önemini değerlendirerek bağlamsal anlamı daha iyi kavrar.
- Bu özellik sayesinde, doğal dil işleme (NLP) görevlerinde özellikle başarılıdırlar. Metin üretimi (Text Generation) ve dil çevirisi (Language Translation) gibi görevlerde dönüştürücüler üstün performans gösterir.
- Dönüştürücü Model Türleri:
- Kodlayıcılar (Encoders)
- Kod çözücüler (Decoders) → Oto-regresif bileşenler içerir.
- Kodlayıcı-kod çözücüler (Encoder-Decoder Models) → Oto-regresif bileşenler içerir.
- Kod çözücüler (Decoders), üretici bileşendir ve oto-regresyon kullanarak üretilen token'ları birbirine bağlı şekilde üretir.
Dönüştürücüler, üretici yapay zeka (Generative AI) alanında büyük dil modellerinin (Large Language Models - LLMs) temelini oluşturur.
Ototörgresif - Autoregressive - Model Kullanım Alanları
Ototörgresif modeller (autoregressive models), özellikle dönüştürücüler (transformers), günümüzde yaygın olarak kullanılmaktadır. Önde gelen üretken yapay zeka (generative AI) modellerinin çoğu dönüştürücülerdir. Bunlara OpenAI’nin GPT ve GPT-4o, Anthropic’in Claude, Meta’nın Llama, Google’ın Gemini ve IBM’in Granite modelleri dahildir. Ototörgresif model kullanım alanları şunlardır: Doğal dil işleme - Natural language processing - NLP: Dönüştürücüler, karmaşık doğal dil sorgularını işleyebilir ve otomatik metin üretimiyle konuşma tarzında yanıt verebilir. Bu özellikleri onları sohbet botları (chatbots) için ideal hale getirir. Örneğin, ChatGPT, OpenAI’nin GPT üretken modelinin bir sohbet botu uygulamasıdır. NLP’nin diğer uygulamaları arasında duygu analizi (sentiment analysis), konuşma tanıma (speech recognition), metinden sese (text-to-speech - TTS) uygulamaları ve belge özetleme (document summarization) bulunmaktadır.
Kod desteği - Coding support: Dönüştürücülerin metin üretiminde üstün olmalarını sağlayan ototörgresif yetenekler, onların kod hata ayıklama (debugging) ve kod parçacıkları üretme (code generation) görevlerini de gerçekleştirmesine olanak tanır.
Zaman serisi tahmini - Time-series forecasting: Ototörgresyon, geçmiş eğilimlere dayanarak gelecekteki değerleri tahmin etmek için zaman serisi tahmininde kolayca uygulanabilir. Zaman serisi tahmini, finansal modelleme (financial modeling), piyasa tahminleri (market predictions) ve hava tahmini (weather forecasting) gibi alanlarda sıkça kullanılır.
Pekiştirmeli öğrenme - Reinforcement learning: Dönüştürücüler, bağımsız karar alma (autonomous decision-making) öğreten bir makine öğrenmesi (machine learning) eğitim tekniği olan pekiştirmeli öğrenmede giderek daha fazla kullanılmaktadır. Ayrıca dönüştürücüler sınıflandırma (classification) görevlerine de uygulanmaktadır.
Difüzyon Modelleri - Diffusion Models
Difüzyon modelleri, giriş verisini yavaş yavaş gürültü (noise) ekleyerek bozar veya difüze eder, ardından oluşturdukları karmaşayı yeni ve benzer verilere dönüştürerek temizler. Bu modeller, gürültüyü eğitildikleri veri kümelerine benzeyen verilere rafine etmeyi öğrenerek yeni veriler üretir. Difüzyon modelleri üç aşamada çalışır:
Difüzyon (Diffusion): Eğitim sırasında model, giriş verisine kademeli olarak Gauss gürültüsü (Gaussian noise) ekler. Bu süreç, Markov zinciri (Markov chain) olarak bilinen matematiksel bir işlemle gerçekleştirilir. Benzetme: Difüzyon sürecini, bir gitaristin amfisinin kazanç düğmesini (gain knob) yavaşça açarak gitar sesini saf bir statik sese dönüştürmesine benzetebiliriz. Rock gitaristleri genellikle müziklerinde bozuk (distorted) bir ses elde etmek için benzer bir yöntem kullanır, ancak burada aşırı bir bozulmadan bahsediyoruz.
Öğrenme (Learning): Model, artık tanınamaz hale gelen verinin nasıl bozulduğunu anlamak için gürültüleme sürecindeki değişiklikleri izler. Difüzyon modelleri bu işlemi her gürültüleme aşamasında tekrarlar.
Ters difüzyon (Reverse diffusion): Model, gürültünün veriyi nasıl değiştirdiğini öğrenerek gürültüleme sürecini tersine çevirmeyi ve giriş verisini yeniden oluşturmayı öğrenir. Ters difüzyonun amacı, Markov zincirinde geriye doğru
hareket ederek Gauss gürültüsünü kaldırmak ve saf veriyi ortaya çıkarmaktır.
Benzetme: Birinci adımdaki gitarist, grup arkadaşlarından sert bir uyarı almış ve kazanç düğmesini tekrar makul bir seviyeye indirmektedir.
ve 2. adımlar, difüzyon modellerini eğitmek için kullanılır. Eğitim tamamlandıktan sonra, difüzyon modelleri rastgele gürültüyü tersine difüze ederek kullanıcının istemine (prompt) uygun veriyi “bulur.”
Difüzyon Model Kullanım Alanları
Genellikle görsel üretimi (image generation) için kullanılan difüzyon modellerinin başka önemli kullanım alanları da vardır:
- Görsel üretimi (Image generation): Difüzyon modelleri, Midjourney, Stable Diffusion ve OpenAI’nin DALL·E 2 gibi popüler görsel üretim (image synthesis) araçlarını güçlendirir. Kullanıcı istemlerine yanıt olarak gerçekçi insan yüzleri de dahil olmak üzere yüksek kaliteli görseller üretebilirler. Not: ABD Telif Hakkı Ofisi, 2023 yılında yapay zeka tarafından üretilen görsellerin telif hakkı korumasına sahip olmadığını belirtti. Bu arada, yapay zeka tarafından üretilen görsellerin telif hakkı ihlali sayılıp sayılmayacağı konusunda süregelen davalar bulunmaktadır.
- İçerik ekleme ve çıkarma (Inpainting & Outpainting): Inpainting: Bir görselin içeriğine ekleme veya çıkarma işlemi. Outpainting: Bir görselin orijinal sınırlarının ötesine genişletilmesi.
- 3D modelleme (3D modeling): Google’ın DreamFusion ve NVIDIA’nın Magic3D modelleri, metin girdilerinden (text inputs) 3D modeller oluşturur.
- Pazar araştırması (Market research): Difüzyon modelleri, zaman içinde nasıl değişiklikler yaşandığını gösterebildiğinden, tüketicilerin bir ürüne nasıl tepki verdiğini anlamada kullanılır.
- Anomali tespiti (Anomaly detection): Difüzyon modelleri verilerin zaman içinde nasıl değiştiğini öğrenebilir, bu da onları belirli veri noktalarının genel eğilimlere uymadığı durumları tespit etmek için ideal hale getirir. Anomali tespiti uygulamaları şunlardır:
Siber güvenlik (Cybersecurity) Dolandırıcılık önleme (Fraud prevention) Hastalık tespiti (Disease detection)
Üretici Çekişmeli Ağlar - Generative Adversarial Networks (GANs)
2014 yılında tanıtılan üretici çekişmeli ağlar (Generative Adversarial Networks - GANs), iki modeli rekabet halinde eşleştiren en erken üretken yapay zeka (generative AI) model türlerinden biridir. Üretici model (generator model) çıktılar üretir ve ayrıştırıcı model (discriminator model) bu çıktıları gerçek mi yoksa sahte mi (authentic or fake) olduğuna karar vermek için değerlendirir. Bu rekabetin amacı, ayrıştırıcının gerçek olarak değerlendirdiği içerikleri üretmektir.
Eğer üretici bir sanat sahtekârı (art forger) ise, ayrıştırıcı bir sanat doğrulayıcısı (art authenticator)dır. Bir sanat tüccarı, sahte bir eseri satın alıp bir müzeye satmaya çalışabilir, ancak önce eserin doğrulama testinden geçmesi gerekir. Sahtekâr ustalaştıkça, doğrulayıcı yeni sahtekârlıkları tespit etmekte zorlanabilir. Sonunda müze, sahte eserlerle dolu bir sergi açabilir.
Gerçekçi çıktılar üreten bu eğitim süreci, aynı zamanda mod çökmesine (mode collapse) yol açabilir. Mod çökmesi, üreticinin eğitim verilerinin bir kısmını göz ardı ederek yalnızca belirli türdeki örneklerle sınırlı kalmasıdır. GAN'lar, difüzyon modelleri (diffusion models) ve dönüştürücüler (transformers) gibi büyük miktarda eğitim verisine ihtiyaç duyar. Bir GAN içindeki her iki ağ (network) da genellikle evrişimli sinir ağları (convolutional neural networks - CNNs) kullanır. CNN'ler, bilgisayarla görme (computer vision) görevlerinde üstün performansıyla bilinen erken dönem sinir ağı türlerinden biridir.
GAN Kullanım Alanları
GAN'lar ağırlıklı olarak bilgisayarla görme (computer vision) ve diğer grafikle ilgili görevlerde kullanılır:
Bilgisayarla Görme (Computer Vision): Bilgisayarla görme, görüntülerden bilgi işlemek için makine öğrenmesini (machine learning) kullanır. Yaygın görevler şunlardır:
- Nesne tespiti ve sınıflandırma (object detection & classification)
- Yüz tanıma (facial recognition)
- İşaret dili çevirisi (sign language translation)
- Nesne takibi (object tracking)
Görsel Üretimi (Image Generation): GAN'lar, difüzyon modellerinden (diffusion models) daha gerçekçi görüntüler üretebilir. Ayrıca daha az eğitim süresi gerektirir ve daha hesaplama verimlidir (compute-efficient). Ancak difüzyon modelleri daha fazla kontrol imkânı (control), esneklik (versatility) ve kararlılık (stability) sunar. Diffusion-GAN çerçevesi (Diffusion-GAN framework), iki model türünün avantajlarını birleştirerek GAN'ları difüzyon ile eğitir.
Anomali Tespiti (Anomaly Detection): GAN'lar normal veri kümelerini (normal datasets) üretmek üzere eğitildiğinde, anomali tespiti (anomaly detection) için kullanılabilir.
- GAN, gerçek dünya verisine dayalı sentetik bir veri kümesi oluşturur ve iki veri kümesi karşılaştırılarak anormallikler belirgin hale getirilir.
- Ayrıştırıcı (discriminator), belirli veri noktalarının sahte olma olasılığını değerlendirerek anomalileri tespit edebilir.
Veri Artırma (Data Augmentation):
- Veri artırma (data augmentation), mevcut verileri kullanarak yeni veri örnekleri oluşturma sürecidir.
- GAN'lar, özellikle CNN'ler için bilgisayarla görme performansını artırmada kullanılır.
- Sentetik veriden (synthetic data) farklı olarak, veri artırma mevcut veriyi genişletir, sıfırdan veri üretmek yerine var olanı zenginleştirir.
Varyasyonel Otokodlayıcılar - Variational Autoencoders (VAEs)
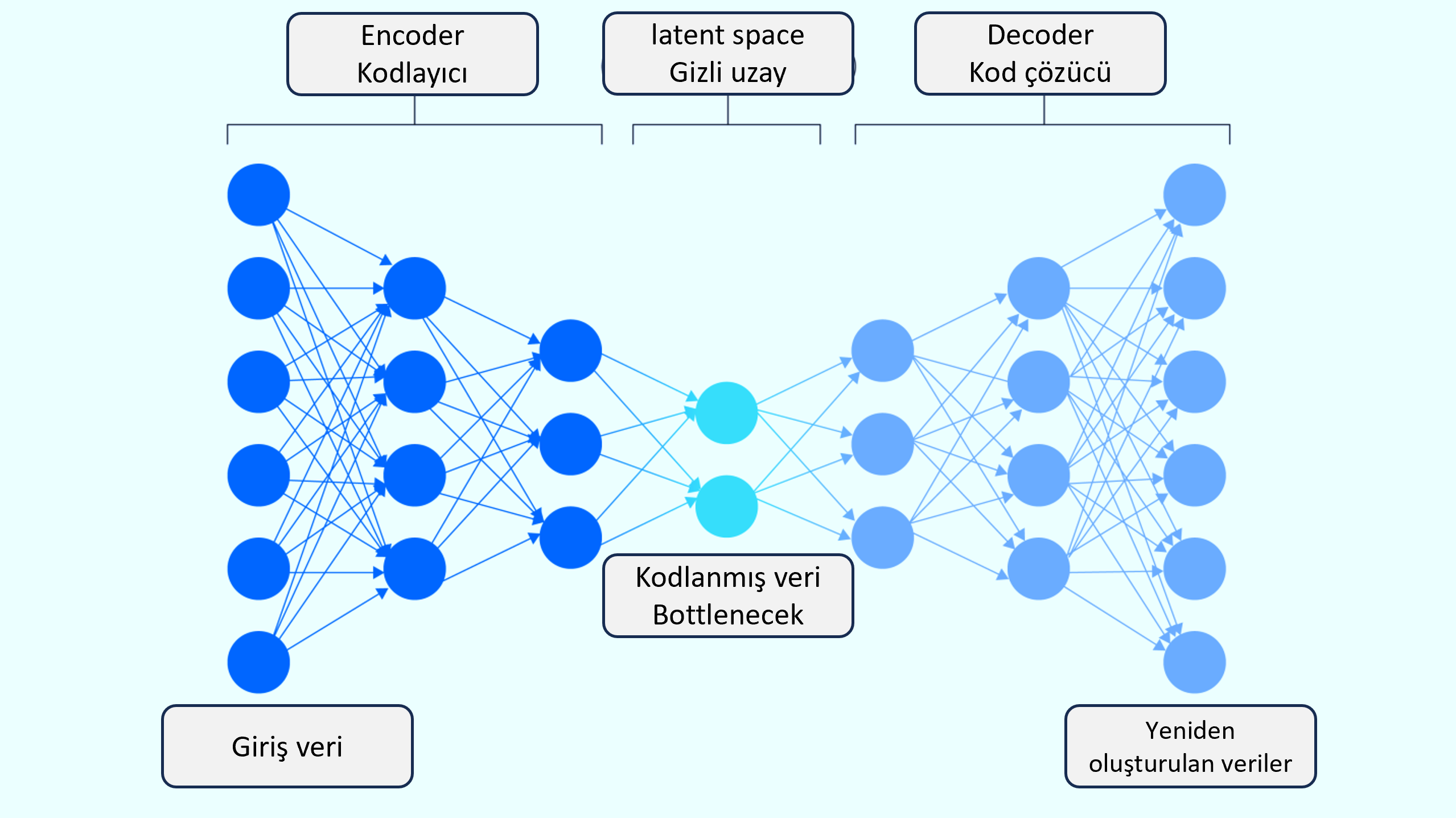
Varyasyonel otokodlayıcılar (Variational Autoencoders - VAEs), giriş verisini sıkıştırır (compress), ardından genişleterek veya çözerek (decode) yeni benzer veriler üretir. VAEs, bir eğitim veri kümesinin dağılımını öğrenir ve bu beklentilere göre kodlanmış örneklerden yeni veri üretir. Tüm otokodlayıcılar (autoencoders) gibi, VAEs iki bileşenden oluşur:
- Kodlayıcı (encoder)
- Çözücü (decoder)
Kodlayıcı (Encoder)
Gizli değişkenleri (latent variables) öğrenir. Gizli değişkenler (latent variables) doğrudan gözlemlenemez ancak veri dağılımında önemli rol oynar. Gizli uzay (latent space), bir veri kümesindeki tüm gizli değişkenlerin genel adıdır. Kodlayıcı, verinin doğru şekilde yeniden oluşturulması için gerekli bilgileri yakalayacak şekilde gizli uzayı modellemesi yapar. Geri kalan tüm değişkenleri hariç tutar.
Çözücü (Decoder)
- Sıkıştırılmış veri temsili olan "dar boğazı (bottleneck)" kullanır.
- Veriyi eski orijinal formuna geri döndürerek genişletir.
- Etkili bir çözücü, orijinal sıkıştırılmadan önceki veriye benzer bir çıktı üretir.
VAE Kullanım Alanları
VAEs, görüntü üretimi (image generation) konusunda difüzyon modelleri (diffusion models) ve GAN'lara kıyasla daha zayıf performans gösterir, ancak diğer alanlarda üstünlük sağlar.
Görüntü Üretimi (Image Generation):
- VAEs, görüntü üretiminde kullanılmaktadır, ancak yaygın uygulamalarda yerini büyük ölçüde difüzyon modellerine bırakmıştır.
- Diğer görüntü üreticilerle karşılaştırıldığında, VAEs “gizli uzayı (latent space)” ortaladığı için daha bulanık görüntüler üretme eğilimindedir.
Genomik (Genomics):
- VAEs, genetikçilerin (geneticists) üreme değerlerini (breeding values) hesaplamalarına yardımcı olur.
- Hayvanın yavrularıyla sağlayacağı potansiyel değerin tahmini yapılabilir.
- Hastalık risk skorlarını (disease risk scores) belirlemede de kullanılır.
Anomali Tespiti (Anomaly Detection):
- VAEs, hem GAN'lara hem de difüzyon modellerine kıyasla daha ucuzdur ve eğitilmesi daha kolaydır.
- Bu nedenle anomali tespiti görevleri için cazip bir seçimdir.
- VAEs ile yeniden oluşturulan veriler, orijinal veriyle karşılaştırılarak normal dağılımdan sapmalar tespit edilir.
Veri Tamamlama (Data Imputation):
VAEs, eksik verileri tamamlamak ve bozulmuş dosyaları eski haline getirmek için kullanılabilir.
Örnekler:
- Ses dosyalarının temizlenmesi (clearing up audio files)
- Videoların parazitlerden arındırılması (denoising videos)
- Tıbbi görüntüleme (medical imaging)
VAEs sıfırdan bulanık görüntüler üretebilir, ancak aynı zamanda önceden bulanık olan bir görüntüyü gürültüsüz hale getirerek (denoising) iyileştirme yapabilir.
Yarı Denetimli Öğrenme (Semisupervised Learning):
- VAEs, eksik etiketlere sahip veri kümelerinin dağılımını öğrenerek sınıflandırıcıları (classifiers) eğitmeye yardımcı olabilir.
- VAEs, aynı zamanda veri artırma (data augmentation) işlemi yaparak sınıflandırıcılar için ekstra eğitim örnekleri üretebilir.
Akış Tabanlı Modeller - Flow-Based Models
Akış tabanlı modeller (Flow-Based Models), verinin dağılımını, tersine çevrilebilir (invertible) veya geri döndürülebilir (reversible) matematiksel dönüşümler dizisiyle öğrenir. Bu süreç, normalleştirici akış (normalizing flow) olarak adlandırılır. VAEs ve GAN'lar veri dağılımlarını tahmin ederken, akış tabanlı modeller doğrudan veri kümesinin olasılık yoğunluk fonksiyonunu (probability density function) öğrenir. Bir veri kümesinde, olasılık yoğunluk fonksiyonu verinin nasıl dağıldığını tanımlar. Normalleştirici akışlar, basit dağılımlardan karmaşık olanlara doğru ilerleyerek hedef değişkenin olasılık yoğunluk fonksiyonunu belirler. Akış tabanlı modeller, başlangıç veri kümesinin istatistiksel özelliklerini koruyan yeni veri örnekleri üretebilir. Tüm üretici modellemelerde olduğu gibi, bu süreç eğitim verilerinden örnekler alarak ve istatistiksel yöntemler uygulayarak benzer, yeni çıktılar üretmeye dayanır.
Akış Tabanlı Model Kullanım Alanları
Akış tabanlı modeller, veri dağılımının doğru tahmin edilmesi gereken durumlarda ön plana çıkar.
Görüntü Üretimi (Image Generation):
- Akış tabanlı modeller, rastgele örneklenmiş gürültüyü (randomly sampled noise) normalizasyon akışlarından geçirerek temiz görüntüler oluşturur.
- Önemli bir 2016 görüntü üretim modeli olan PixelCNN, görüntüleri piksel bazında modelleyerek dönüşümler dizisine otoregresyon (autoregression) uygular.
Kesin Yoğunluk Tahmini (Accurate Density Estimation):
- Yoğunluk tahmini (density estimation), gözlemlenebilir verilere dayanarak veri kümesinin olasılık yoğunluk fonksiyonunu belirleme sürecidir.
- Akış tabanlı modeller karmaşık veri dağılımlarını doğru bir şekilde temsil edebilir.
- Ancak, uzun menzilli bağımlılıkları (long-range dependencies) öğrenme konusunda dönüştürücülere (transformers) kıyasla daha zayıftır.
Moleküler Grafik Üretimi (Molecular Graph Generation):
Akış tabanlı modeller, yeni moleküler yapıları grafikler (graphs) şeklinde modelleyerek moleküler grafik üretiminde kullanılır. Bu teknik, bilim insanları ve mühendisler için yeni ilaçlar ve malzemeler keşfetmede önemli bir araçtır.
Üretici Modeller ve Halüsinasyonlar - Generative Models and Hallucinations
Üretici modellerde etkileyici sonuçlara yol açan süreçler, bazen yanlış veya yanıltıcı bilgiler üretmelerine neden olabilir.
- Bu tür yanlış üretimler "halüsinasyon (hallucination)" veya "uydurma (confabulation)" olarak adlandırılır.
- Halüsinasyonlar, modelin eğitim veri kümesinde gerçekte var olmayan desenleri algılaması sonucunda oluşur.
Örnek:
Seinfeld Hatası
Bir dil modeli (örneğin, GPT-4o mini) aşağıdaki soruya yanıt vermiştir:
"Seinfeld’in hangi bölümünde Kramer Bangladeş’e gidiyor?"
Yanıt:
Kramer, "The Little Jerry" adlı 145. bölümde Bangladeş’e gider. Bu, Seinfeld’in 145. bölümüdür ve 8. sezonda yayınlanmıştır. Bu bölümde, Kramer Bangladeş’ten bir oyuncak ithal etme planına karışır.
Gerçekte:
- "The Little Jerry" bölümü 145. bölümdür, ancak Kramer bu bölümde yalnızca bir horoz satın alıp eğitmektedir.
- Aynı soru tekrar sorulduğunda, model yeni bir yanlış bilgi üretmiştir:
Yeni Yanıt:
Kramer, "The Maldives" adlı 9. sezonun 18. bölümünde Bangladeş’e gider.
Gerçekte:
- Seinfeld’in 9. sezonunun 18. bölümü "The Frogger"dır ve Kramer yalnızca polis karakoluna kadar gider.
- Seinfeld dizisinde "The Maldives" adlı bir bölüm yoktur ve Kramer hiçbir zaman Bangladeş’e gitmez.
Aynı şekilde:
- Otoregresif modeller (autoregressive models) olan GPT gibi modeller yanlış bilgiler üretebilir.
- Görüntü üretimi için kullanılan difüzyon modelleri (diffusion models) bazen gerçek dünya nesnelerini yanlış bir şekilde tasvir edebilir.
Halüsinasyonları Azaltma Yöntemleri
Üretici yapay zeka modellerinde halüsinasyonları tamamen önlemek şu an mümkün değildir, ancak aşağıdaki yöntemler etkili olabilir: Açık Talimatlar (Clear Prompting): Kullanıcı talimatı ne kadar açık olursa, yapay zekanın yanıtı o kadar odaklı olur.
Odaklı Yönlendirme (Focused Direction): AI’ye doğru ve doğrulanabilir bilgi üretmesi için net bir rol verilmelidir.
Yüksek Kaliteli Veri (High-Quality Data): Güncel ve güvenilir eğitim verileri kullanmak, yanıtların daha doğru olmasını sağlar.
İnsan Doğrulaması (Human Verification): AI tarafından üretilen sonuçlar, uzmanlar tarafından doğrulanmadan doğrudan kullanılmamalıdır.
RAG ve İnce Ayar (RAG and Fine-Tuning): RAG kullanarak güvenilir veri kaynakları eklemek ve modelin alanına özel ince ayar yapmak halüsinasyonları azaltabilir.
🚀 Yapay Zeka Paketi’ne kaydolarak, yapay zeka bilginizi ileri seviyeye taşıyabilir ve yapay zeka alanında güçlü bir başlangıç yapabilirsiniz!
.png)

