

 Programlama Akademi
Programlama Akademi
DeepSeek R1 RAG Sohbet Robotu
Bilgi Getirme Destekli Üretim (Retrieval-Augmented Generation - RAG), yapay zeka uygulamalarında doğru, sağlam temellere dayanan ve bağlamsal olarak uygun cevaplar üretebilmek için harici kaynaklardan bilgi getirip sentezleyen güçlü bir yaklaşım olarak ortaya çıkmıştır.
Bu eğitimde, DeepSeek-R1 modelini ve hayvanlar hakkında yazılan deneme kitabı ile bilgi tabanı olarak kullanarak RAG tabanlı bir sohbet botu oluşturmayı adım adım anlatacağız.
Eğitim sonunda şunları yapabileceksiniz:
- Kitaptan alınan bilgilere dayalı olarak soruları yanıtlayan yerel bir RAG uygulaması oluşturmak,
- Gradio arayüzü kullanarak chatbot'unuzun kullanıcılarla etkileşime girmesini sağlamak,
- RAG sistemlerinin çalışma prensiplerini anlayarak LLM tabanlı uygulamalara harici bilgi entegre etmek.
🚀 Yapay Zeka Paketi’ne kaydolarak, bilginizi ileri seviyeye taşıyabilir ve yapay zeka alanında güçlü bir başlangıç yapabilirsiniz!
RAG Neden Önemlidir?
Geleneksel dil modelleri, eğitim süreçlerinde edindikleri bilgiyi kullanarak metin üretirler. Ancak bu modeller:
- Güncel veya spesifik bilgiler gerektiren durumlarda sınırlı kalabilir,
- Eğitildikleri tarihten sonra oluşan yeni bilgileri doğrudan öğrenemezler,
- Yanıtlarında bazen halüsinasyon (uydurma bilgi üretme) riski taşıyabilirler.
RAG yaklaşımı, modelin harici kaynaklardan (örneğin dokümanlar, veritabanları, web sayfaları) gerçek zamanlı bilgi almasını sağlayarak yanıtların doğruluğunu artırır. Bu sayede model, önceden eğitildiği veriyle sınırlı kalmadan daha güvenilir ve güncel cevaplar üretebilir.
Bu eğitimde, LLM'leri nasıl genişletebileceğinizi ve harici bilgileri entegre ederek daha güçlü bir yapay zeka uygulaması oluşturabileceğinizi öğreneceksiniz.
Neden RAG ile DeepSeek-R1 Kullanmalıyız?
DeepSeek-R1, optimize edilmiş performansı, gelişmiş vektör arama yetenekleri ve yerel kurulumlardan ölçeklenebilir dağıtımlara kadar farklı ortamlarda esnekliği sayesinde RAG tabanlı sistemler için ideal bir seçimdir. İşte onu etkili kılan bazı nedenler:
- Yüksek performanslı bilgi getirme: DeepSeek-R1, büyük doküman koleksiyonlarını düşük gecikme süresiyle işler.
- Hassas alaka sıralaması: Anlamsal benzerlik hesaplayarak en doğru pasajları getirir.
- Maliyet ve gizlilik avantajı: DeepSeek-R1’i yerel olarak çalıştırarak API ücretlerinden kaçınabilir ve hassas verileri güvende tutabilirsiniz.
- Kolay entegrasyon: Chroma gibi vektör veri tabanlarıyla sorunsuz bir şekilde entegre olur.
- Çevrimdışı çalışma yeteneği: Model indirildikten sonra internet bağlantısı olmadan da bilgi getirme sistemleri oluşturabilirsiniz.
DeepSeek-R1 ile RAG Sohbet Botu Geliştirme
Bu demo projesinde, DeepSeek-R1 ve Gradio kullanarak bir RAG sohbet botu geliştirmeye odaklanacağız.
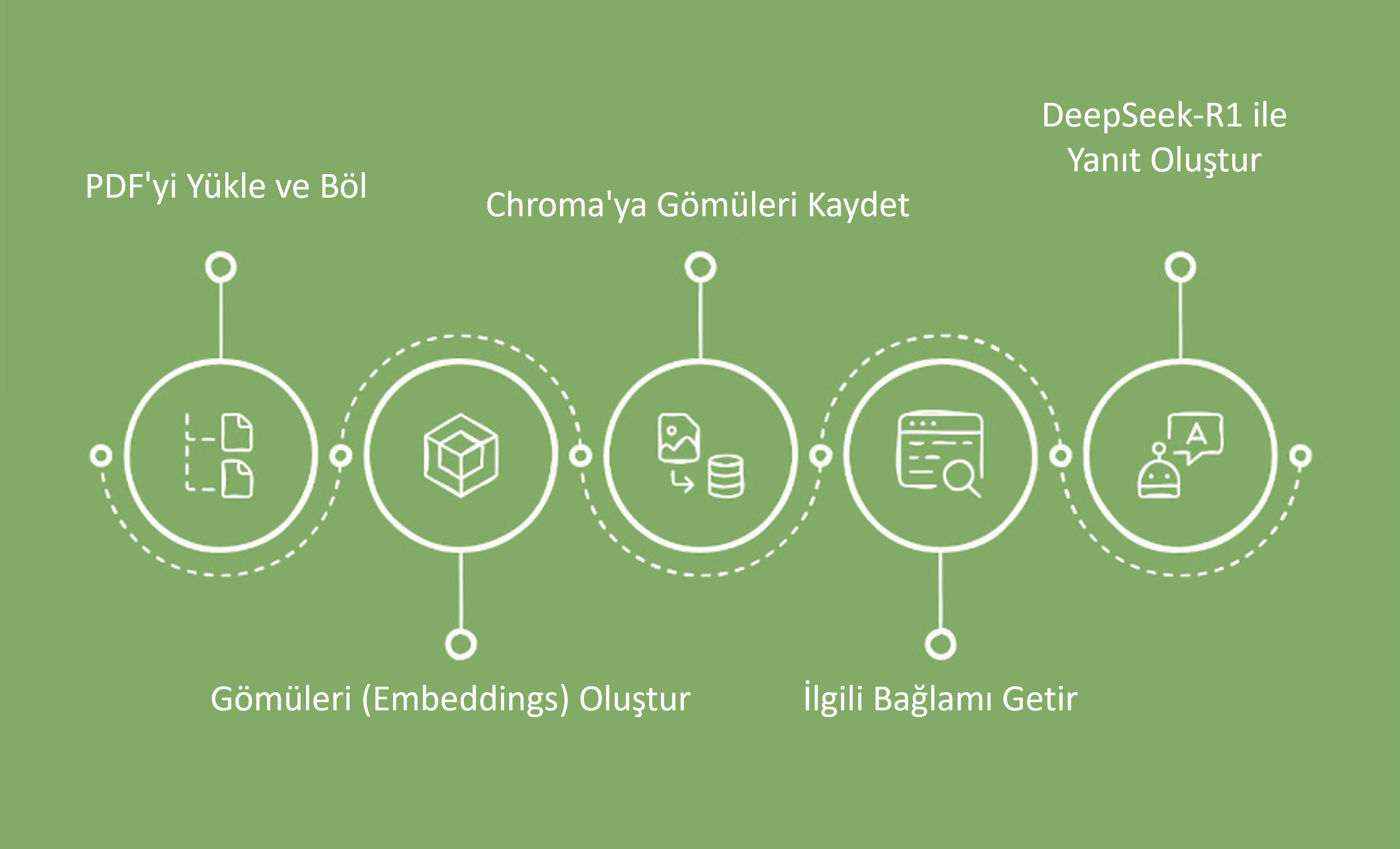
Bu süreç, DeepSeek-R1 ve Chroma kullanarak bilgi getirme destekli üretim (RAG) tabanlı bir sistem oluşturmayı adım adım açıklar.
PDF'yi Yükleme ve Bölme
PDF belgesinden metin çıkarılır ve daha küçük parçalara (chunks) ayrılır. Bu işlem, daha verimli bilgi getirme ve ilgili pasajların seçilmesini sağlar.
Gömme Vektörleri Oluşturma
Bölünen metin parçaları için vektör temsilleri (embeddings) oluşturulur. Embeddings, metnin anlamsal yapısını sayısal bir forma dönüştürerek benzer içeriklerin karşılaştırılmasını sağlar.
Gömme Vektörlerini Chroma'ya Kaydetme
Oluşturulan embedding'ler Chroma vektör veri tabanına kaydedilir. Chroma, metin parçalarını ve onların vektör temsillerini saklayarak daha sonra hızlı bir şekilde arama yapılmasını sağlar.
İlgili Bağlamı Getirme
Kullanıcı bir soru sorduğunda, sistem Chroma veri tabanında en alakalı metin parçalarını arar. En iyi eşleşen k tane (top-k) metin parçası getirilerek, cevabın oluşturulması için bağlam sağlanır.
DeepSeek-R1 ile Cevap Üretme
Getirilen metin parçaları, DeepSeek-R1 modeline bağlam olarak sunulur. Model, bu bağlamı kullanarak soruyla ilgili en doğru cevabı üretir.
Adım 1: Ön Gereksinimler
Başlamadan önce, aşağıdaki araçların ve kütüphanelerin yüklü olduğundan emin olalım:
Python 3.8+
Projemizi çalıştırabilmek için Python'un en az 3.8 sürümüne ihtiyacımız var.
Langchain
Dil modellerini (LLM) daha verimli kullanabilmek için geliştirilmiş bir kütüphanedir. Özellikle RAG tabanlı uygulamalar için güçlü araçlar sağlar.
Chromadb
Vektör veri tabanı olarak kullanılır ve metin parçalarını sayısal formatta saklar. Bilgi getirme sürecinde hızlı ve etkili aramalar yapmamıza yardımcı olur.
Gradio
Yapay zeka modelleriyle kullanıcı dostu web arayüzleri oluşturmayı kolaylaştırır. Sohbet botunu test etmek için basit bir arayüz sağlar.
pymupdf
PDF dosyalarını okuma ve metin çıkarma işlemleri için kullanılır.
- PDF’den içerik alarak bilgiyi parçalara ayırmamıza olanak tanır.
Langchain-Community
Langchain'in topluluk sürümü, güncellenmiş entegrasyonlar ve yeni özellikler içerir. En son araçlarla uyumlu çalışmasını sağlar.
Langchain-Ollama
Ollama, yerel olarak çalışabilen LLM modellerini destekler. İnternet bağlantısı olmadan büyük dil modellerini çalıştırmak için kullanılabilir.
Gerekli bağımlılıkları yüklemek için aşağıdaki komutları çalıştırın:
pip install langchain chromadb gradio ollama pymupdf
pip install -U langchain-community
pip install -U langchain-ollama
Yukarıdaki bağımlılıklar yüklendikten sonra, rag.py bir dosya oluşturarak aşağıdaki import komutlarını yazın:
# Gerekli kütüphaneleri içe aktarıyoruz
import ollama # Ollama tabanlı LLM modellerini kullanmak için
import re # Metin işleme ve düzenli ifadelerle eşleşme yapmak için
import gradio as gr # Kullanıcı arayüzü oluşturmak için Gradio kütüphanesi
from concurrent.futures import ThreadPoolExecutor # Çoklu iş parçacığı (multithreading) yönetimi için
# Metni küçük parçalara ayırmak için bir modül
from langchain.text_splitter import RecursiveCharacterTextSplitter
# PDF dosyalarını yüklemek için
from langchain_community.document_loaders import PyMuPDFLoader
# Ollama'nın embedding (gömme vektör) modelini kullanarak metinleri sayısal vektörlere dönüştürmek için
from langchain_ollama import OllamaEmbeddings
# ChromaDB'nin yapılandırma ayarlarını almak için
from chromadb.config import Settings
# ChromaDB istemcisi oluşturmak için
from chromadb import Client
# Chroma'yı Langchain'in vektör veri deposu olarak kullanmak için
from langchain_community.vectorstores import Chroma
Adım 2: Belgeyi PyMuPDFLoader ile Yükleme
PyMuPDFLoader, PDF belgelerini yüklemek için kullanılan bir kütüphanedir. Bu adımda, bir PDF dosyasını yükleyerek içerik üzerinde işlem yapabiliriz.
belge_yukleyici = PyMuPDFLoader("test.pdf") # PDF dosyasını yükler
belgeler = belge_yukleyici.load() # PDF içeriğini işler ve döndürür
Burada test.pdf adlı bir PDF dosyası kullanılıyor, ancak herhangi bir PDF kitabını veya belgeyi kullanabilirsiniz. Yüklenen içerik, belgeler değişkenine atanır ve daha sonra doğal dil işleme (NLP) veya bilgi çıkarımı için kullanılabilir.
test.pdf dosyasının içeriği şu şekildedir:
Hayvanların Dünyası Hayvanlar, doğadaki en çeşitli canlı gruplarından biridir. Dünyanın her köşesinde, farklı ekosistemlerde yaşayan milyonlarca tür bulunmaktadır. Kara, hava ve su ortamlarında yaşamlarını sürdüren bu canlılar, doğanın dengesini korumada önemli bir rol oynar. Hayvanların Sınıflandırılması Bilim insanları, hayvanları bazı temel özelliklerine göre gruplara ayırmıştır. Başlıca hayvan grupları şunlardır: 1. Memeliler Memeliler, yavrularını sütle besleyen sıcak kanlı hayvanlardır. Genellikle doğurarak ürerler ve vücutlarını kaplayan kıllara sahiptirler. Öne çıkan memeliler: Aslanlar: Ormanların ve savanların güçlü avcılarıdır. Sosyal hayvanlardır ve genellikle sürüler halinde yaşarlar. Filler: Karada yaşayan en büyük memelilerdendir. Güçlü hafızaları ve sosyal yapıları ile bilinirler. Yunuslar: Denizde yaşayan memelilerdir. Oldukça zeki ve sosyal canlılardır, sürüler halinde hareket ederler. 2. Kuşlar Kuşlar, tüyleri olan ve genellikle uçabilen hayvanlardır. Yumurtlayarak ürerler ve birçok türü göçmen kuş olarak uzun mesafeler kat eder. Öne çıkan kuşlar: Kartallar: Keskin gözleri ve güçlü pençeleriyle bilinirler. Genellikle yüksek noktalarda yuva yaparlar. Penguenler: Uçamayan bir kuş türüdür, ancak su altında çok hızlı hareket edebilirler. Papağanlar: Zeki ve konuşma yetenekleriyle tanınırlar. İnsanlarla güçlü bir bağ kurabilirler. 3. Sürüngenler Sürüngenler, soğukkanlı hayvanlardır ve genellikle yumurtlayarak ürerler. Derileri pullarla kaplıdır. Öne çıkan sürüngenler: Timsahlar: Güçlü çeneleri ve suya adapte olmuş yapıları ile bilinirler. Avlarını bekleyerek ve aniden saldırarak yakalarlar. Yılanlar: Zehirli ya da zehirsiz türleri bulunur. Zehirli yılanlar, avlarını etkisiz hale getirmek için güçlü toksinler kullanır. Bukalemunlar: Renk değiştirme yetenekleriyle ünlüdürler. Bu özelliklerini hem kamuflaj için hem de duygularını ifade etmek için kullanırlar.
Adım 3: Belgeyi Küçük Parçalara Ayırma
Çıkarılan metni daha iyi bağlam alımı için küçük, üst üste binen parçalara böleceğiz.RecursiveCharacterTextSplitter() fonksiyonu içinde parça boyutunu ve örtüşme miktarını sisteminize göre ayarlayabilirsiniz.
# Belgeyi küçük parçalara ayırma
metin_bolucu = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
parcalar = metin_bolucu.split_documents(belgeler)
Açıklamalar: chunk_size=1000: Her bir parçanın maksimum 1000 karakter uzunluğunda olmasını sağlar chunk_overlap=200: Parçalar arasında 200 karakterlik bir örtüşme olmasını sağlar. Bu, bağlam bütünlüğünü koruyarak parçalar arasında bilgi kaybını önler split_documents(belgeler): PDF’den çıkarılan belgeler listesini alır ve belirtilen ayarlara göre küçük parçalara böler parcalar değişkeni, oluşturulan parçaları içeren bir liste olarak döndürülür Artık Çıkarılan Metin Parçaları Gömülere Dönüştürülmeye Hazırdır.
Adım 4: DeepSeek-R1 Kullanarak Gömüler Oluşturma
Belge gömülerini oluşturmak için DeepSeek-R1 tabanlı Ollama Embeddings kullanacağız. Belgenin boyutuna bağlı olarak gömü oluşturma işlemi zaman alabilir, bu nedenle daha hızlı işlem için paralelleştirilmesi tercih edilir.
Not: Varsayılan olarak model="deepseek-r1" ifadesi 7B parametreli modeli kullanır.
İhtiyaca göre bu değer 8B, 14B, 32B, 70B veya 671B olarak değiştirilebilir.
Aşağıdaki model adında X yerine model boyutunu yazabilirsiniz:model="deepseek-r1:X"
# Ollama gömüleri (embeddings) başlatma
gomuleme_fonksiyonu = OllamaEmbeddings(model="deepseek-r1")
# Gömüleri paralel olarak oluşturma
def gomuleme_olustur(parca):
return gomuleme_fonksiyonu.embed_query(parca.page_content)
with ThreadPoolExecutor() as executor:
gomuler = list(executor.map(gomuleme_olustur, parcalar))
Yukarıdaki fonksiyon, yüksek boyutlu anlamsal gömüler oluşturmak için Ollama aracılığıyla DeepSeek-R1 modelini başlatır. Bu gömüler daha sonra benzerlik tabanlı belge getirme işlemlerinde kullanılacaktır.
generate_embedding() fonksiyonu, bir belge parçasının metnini alır ve onun gömüsünü oluşturur.
Son olarak, ThreadPoolExecutor(), her bir parçaya generate_embedding() fonksiyonunu eşzamanlı olarak uygular ve gömüleri bir liste halinde toplar. Bu yöntem, ardışık (sequential) çalıştırmaya kıyasla daha hızlı işlem sağlar.
Adım 5: Gömüleri Chroma Vektör Deposuna Kaydetme
Gömüleri ve ilgili metin parçalarını yüksek performanslı bir vektör veritabanı olan Chroma içinde saklayacağız.
# Chroma istemcisini başlat ve koleksiyonu oluştur/sıfırla
istemci = Client(Settings())
koleksiyon_adi = "temelleri_llms"
# Koleksiyon varsa sil
if koleksiyon_adi in [kol.name for kol in istemci.list_collections()]:
istemci.delete_collection(name=koleksiyon_adi)
# Koleksiyonu oluştur ve verileri ekle
koleksiyon = istemci.create_collection(name=koleksiyon_adi)
for indeks, parca in enumerate(parcalar):
koleksiyon.add(documents=[parca.page_content], metadatas=[{'id': indeks}], embeddings=[gomuler[indeks]], ids=[str(indeks)])
Gömüleri saklamak için aşağıdaki adımları takip ediyoruz:
Chroma istemcisini başlatın ve koleksiyonu sıfırlayın:
Client(Settings())ile Chroma istemcisini başlatarak vektör deposunu yönetiyoruz.- Hata önlemek için
client.delete_collection()kullanarak mevcut koleksiyonlardan adınıza benzer olanları silin. - Yeni bir koleksiyon oluşturmak için
client.create_collection()kullanarak belge parçalarını ve gömülerini saklayacağınız koleksiyonu oluşturun.
Belge parçaları üzerinde yineleme yapın:
- Her belge parçasını ve ona karşılık gelen gömüyü benzersiz bir dize kimliği (ID) ile birlikte işleyin.
Parçaları ve gömüleri Chroma'ya ekleyin:
- Her bir parça için
collection.add()fonksiyonunu kullanarak şunları saklayın:- Belge içeriği →
chunk.page_content - Parça kimliği için metadata →
{'id': idx} - Benzerlik tabanlı geri getirme için gömü vektörü
- Benzersiz bir kimlik (ID) dizesi ile girişleri tanımlama
- Belge içeriği →
Bu yapı, her belge parçasının doğru şekilde indekslenmesini sağlayarak verimli vektör tabanlı arama yapılmasını mümkün kılar.
Adım 6: Getiriciyi (Retriever) Başlatma
Chroma getiricisini (retriever) başlatacağız ve sorgular için aynı DeepSeek-R1 gömülerini kullandığından emin olacağız.
# Retriever başlatma
retriever = Chroma(collection_name=koleksiyon_adi, client=istemci, embedding_function=gomuleme_fonksiyonu).as_retriever()
Chroma getiricisi, "foundations_of_llms" koleksiyonuna bağlanır ve kullanıcı sorgularını gömmek için Ollama aracılığıyla DeepSeek-R1 gömülerini kullanır. Bağlam odaklı yanıtlar vermek için vektör benzerliğine dayalı olarak en alakalı belge parçalarını getirir.
Adım 7: RAG Boru Hattını (Pipeline) Tanımlama
Sonraki adımda, en alakalı metin parçalarını getirecek ve DeepSeek-R1'in yanıt üretmesi için uygun şekilde biçimlendireceğiz.
def baglam_getir(soru):
# İlgili belgeleri getirir ve birleştirir.
sonuclar = retriever.invoke(soru)
# Alınan içeriği birleştir
baglam = "\n\n".join([doc.page_content for doc in sonuclar])
return baglam
retrieve_context fonksiyonu, kullanıcı sorgusunu DeepSeek-R1 ile gömer ve Chroma getiricisi aracılığıyla en alakalı belge parçalarını getirir. Daha sonra, getirilen parçaların içeriğini tek bir bağlam dizesi olarak birleştirerek sonraki işlemler için hazır hale getirir.
🚀 Yapay Zeka Paketi’ne kaydolarak, RAG bilginizi ileri seviyeye taşıyabilir ve yapay zeka alanında güçlü bir başlangıç yapabilirsiniz!
Adım 8: Bağlamsal Yanıtlar İçin DeepSeek-R1'e Sorgu Gönderme
Artık elimizde soru ve getirilen bağlam var. Şimdi, Ollama aracılığıyla DeepSeek-R1'e göndererek nihai yanıtı alacağız.
def deepseek_sorgula(soru, baglam):
# DeepSeek-R1 modeline sorgu gönderir.
giris_istem = f"Soru: {soru}\n\nBağlam: {baglam}"
# Ollama kullanarak DeepSeek-R1'i sorgula
yanit = ollama.chat(
model="deepseek-r1",
messages=[{"role": "user", "content": giris_istem}]
)
# Temizle ve yanıtı döndür
yanit_icerik = yanit["message"]["content"]
temiz_cevap = re.sub(r"<think>.*?</think>", "", yanit_icerik, flags=re.DOTALL).strip()
return temiz_cevap
Nihai yanıtı almak için önce kullanıcı sorusunu ve getirilen bağlamı yapılandırılmış bir istem (prompt) olarak birleştiriyoruz. Daha sonra, bu istemi Ollama aracılığıyla DeepSeek-R1 modeline göndererek yanıt alıyoruz.
Son olarak, gereksiz etiketleri temizleyerek nihai yanıtı döndürüyoruz.
Adım 9: Gradio Arayüzünü Oluşturma
RAG boru hattımız hazır. Şimdi, kullanıcıların bilgi tabanıyla (bu durumda "Foundations of LLMs") ilgili sorular sorması için Gradio kullanarak etkileşimli bir arayüz oluşturacağız.
def soru_sor(soru):
# RAG kullanarak bağlamı alın ve bir cevap oluşturun
baglam = baglam_getir(soru)
cevap = deepseek_sorgula(soru, baglam)
return cevap
# Gradio arayüzü
arayuz = gr.Interface(
fn=soru_sor,
inputs="text",
outputs="text",
title="RAG Sohbet Robotu",
description="Seçtiğiniz kitaptan istediğiniz soruyu sorun. Cevap deepseek-r1 modeli tarafından desteklenecektir.",
submit_btn="Soruyu Sor",
clear_btn="Temizle"
)
arayuz.launch()
ask_question() fonksiyonu, Chroma getiricisini (retriever) kullanarak ilgili bağlamı getirir ve DeepSeek-R1 aracılığıyla nihai yanıtı oluşturur.
Gradio arayüzü, gr.Interface() ile oluşturularak kullanıcıların etkileşimli bir şekilde sorular sormasını ve bağlam temelli doğru yanıtlar almasını sağlar.
Şimdi kodu çalıştırmak için proje dizininde komut istemini (terminali) açacağız ve aşağıdaki komutu çalıştıracağız:
python rag.py
Ekranda http://127.0.0.1:7860/ bağlantısı görünecektir. Bu bağlantıyı kopyalayarak tarayıcıya yapıştırın.
Tebrikler! Artık LLM'ler hakkında sohbet edebilen yerel olarak çalışan bir sohbet botuna sahipsiniz.

Sonuç
Bu eğitimde, DeepSeek-R1 ve Chroma kullanarak RAG tabanlı yerel bir sohbet botu oluşturduk. Bu sistem, geniş bir bilgi tabanına dayanarak sorulara doğru ve bağlam açısından zengin yanıtlar vermeyi sağlar.
.png)
